비개발자가 Impact에 거절당한 날 밤, 나는 ACE를 짜기 시작했다
이 글은 제가 ACE(Affiliate Content Engine)를 직접 만들면서 기록한 경험담입니다. 이 글에는 어필리에이트 링크가 포함되어 있지 않습니다. 언급되는 도구는 모두 제가 실제로 사용 중인 것들이며, 링크는 투명성을 위해 공개된 슬러그 리다이렉트(/go/{slug})를 통해 이동합니다.

왜 이 문제가 중요한가
2026년 3월의 어느 새벽, 나는 Impact Marketplace 대시보드 앞에서 다섯 번째 거절 메일을 받았다. 이유는 단 한 줄이었다. “도메인 권위가 충분하지 않습니다.” 내가 산 .xyz 도메인은 30일도 안 된 상태였고, 백링크는 0, Ahrefs DR은 아예 측정조차 되지 않았다. 그 거절 메일은 IMPACT_MARKETPLACE_DECLINED.md라는 파일로 내 레포에 지금도 남아 있다. 나는 그걸 삭제하지 않기로 했다. 출발선을 잊지 않기 위해서다.
나는 개발자가 아니다. 엑셀 VBA로 업무 자동화를 15년 하다가, 작년에 처음으로 파이썬을 제대로 들여다보기 시작했다. 그런 내가 어필리에이트 마케팅을 시작하려고 하니 벽은 명확했다. 큰 플랫폼은 권위 없는 신규 도메인을 안 받아주고, 받아주는 작은 네트워크는 단가가 낮다. 그리고 기존 SaaS 콘텐츠 도구들은 월 99달러에서 299달러를 받으면서도 정작 내가 필요한 “한국어 1인칭 EEAT 포스트 + 어필리에이트 링크 + Schema.org 자동 주입”을 한 번에 해주는 물건이 없었다. 여러 SaaS를 조합해봤지만 출력물이 전부 AI 냄새가 났다. 보라 그라디언트 이미지, “포괄적인 솔루션을 제공합니다” 같은 문장, 같은 템플릿으로 찍어낸 비교표. 내가 읽기 싫은 글을 내가 쓸 수는 없었다.
그날 밤 나는 결심했다. 내가 쓸 파이프라인을 내가 직접 짜자. 어차피 콘텐츠 전략은 내 머리에 있고, 코드는 Claude Code가 써줄 수 있다. 월 40달러 구독료 안에서 — Cursor Pro 20달러와 Claude Pro 20달러 — 나만의 콘텐츠 공장을 세울 수 있는지 실험해보자. 어필리에이트 승인이 안 나오는 지금이 오히려 기회였다. 어차피 링크가 없으니 순수한 “경험 기반 글쓰기”로 EEAT 신호를 쌓는 데 집중할 수 있었다. Google이 2024년부터 가중치를 올린 그 EEAT 말이다.
경쟁 지형을 한 번 더 생각해봤다. 어필리에이트 마케팅 블로그는 지난 2년간 두 가지 방향으로 양극화됐다. 한쪽 끝은 초대형 퍼블리셔들이 프로그래매틱 SEO와 AI 대량 생산으로 쏟아내는 “정답 같은 생김새의 빈 글”이다. 반대쪽 끝은 1인 크리에이터가 자기 손으로 쓴, 검색엔진이 좋아하지 않지만 사람이 실제로 읽는 블로그다. 나는 두 번째가 장기적으로 이긴다고 믿는다. Google이 헬프풀 콘텐츠 업데이트를 세 번 돌리면서 분명해졌다. 사람이 실제로 읽는 글만 살아남는다. 내 전략은 사람이 실제로 읽는 글을 “기계적 품질 검사”와 “반복 가능한 파이프라인”으로 뒷받침하는 것이다. 둘은 모순이 아니다. 문체는 1인칭으로 두고, 인프라는 자동화로 두는 구조다.
이 글은 그 실험의 “왜”에 대한 기록이다. 나머지 5편은 각각의 “어떻게”를 다룬다. 아키텍처를 왜 5단계로 쪼갰는지, DB를 왜 Google Sheets로 골랐는지, 블로그 생성을 왜 서브에이전트에 위임했는지, Quality Gate는 어떤 기계적 검사를 하는지, Schema.org JSON-LD는 어떻게 WordPress에 자동 주입되는지. 각 글은 독립적으로 읽히지만, 이 허브 글이 뒷받침하는 “왜 이걸 내가 직접 짰는가”라는 질문에 대한 내 대답은 오직 여기에 있다.
한 가지 미리 말해두고 싶은 건, 이 시리즈는 “튜토리얼”이 아니라 “빌드 저널”이라는 점이다. 나는 내가 실제로 한 일을 적는다. 내가 실제로 틀린 것도 적는다. 그리고 지금도 내가 확신하지 못하는 부분도 적는다. 완성된 전문가의 가이드가 필요한 독자라면 더 적합한 글이 많다. 반면 “비개발자가 6개월 전에는 어떻게 시작했는가”가 궁금한 독자라면, 이 6편이 아마 지금 웹에 존재하는 것 중 가장 구체적인 기록일 것이다. 내 돈과 내 시간으로 실제로 겪었기 때문이다.
내가 실제로 한 것
나는 먼저 A4 노트에 ACE(Affiliate Content Engine)라는 이름을 손으로 적었다. 그 아래 5단계 파이프라인을 그렸다. Discovery → Brief → Generate → Quality Gate → Publish. 이 다이어그램은 지금도 내 책상 옆에 붙어 있다. 화살표가 삐뚤고, 박스 안의 글씨는 다 다른 크기다. 그런데 이 지저분한 노트가 이후 3주 동안 내가 길을 잃을 때마다 돌아올 기준점이 됐다.
다음 날 아침, Cursor를 열고 빈 폴더에서 첫 커밋을 찍었다. a4dfd01 chore: initialize clean repository. 이게 ACE 레포의 출생 신고서다. 거기서부터 나는 매일 밤 2~3시간씩 코드를 붙여나갔다. 개발자가 아니라서 문법이 기억 안 날 때마다 Claude Code에게 “이거 왜 안 돼?”라고 물었고, Anthropic 공식 문서를 열어놓고 서브에이전트 문법을 학습했다. 매일 밤 기록은 handoff.md라는 파일에 남겼다. 세션을 닫기 전에 “오늘 뭘 했고, 내일 뭘 해야 하고, 지금 막힌 곳은 어디인지”를 3~5줄로 적었다. 이게 다음날 Claude Code를 다시 켰을 때의 컨텍스트 복원 장치였다.
3주가 지났을 때 내 레포의 상태는 이랬다.
$ git log --oneline | head -10
1a55ecd feat(foundation): add foundation content type end-to-end
ff4964f docs: update handoff.md with Session 3 changes
4a17d6b docs: add handoff.md with full project history and Phase 4 plan
8fc9917 feat(quality): add Phase 3 quality gate and link inserter
9ebcd27 feat(generators): add Phase 2 blog/threads prompt generators
30bde34 feat(discovery): add Phase 1B discovery pipeline
924e8cf feat(briefs): add brief read/list/validate scripts
2dac25d feat(sheets): add google sheets client with service account
...
a4dfd01 chore: initialize clean repository
나는 이 커밋 히스토리를 자주 들여다본다. 각 커밋이 정확히 하나의 단계에 매핑돼 있기 때문이다. 2dac25d가 Google Sheets 연동, 924e8cf가 brief 읽기·검증, 30bde34가 Discovery 파이프라인, 9ebcd27가 블로그·Threads 생성기, 8fc9917가 Quality Gate와 링크 인서터, 4a17d6b·ff4964f가 세션 핸드오프 문서화, 그리고 1a55ecd가 Foundation 콘텐츠 타입이다. 디버깅할 때 “어디서 무언가가 깨졌을 가능성이 있는가”를 추적하는 지도가 된다.
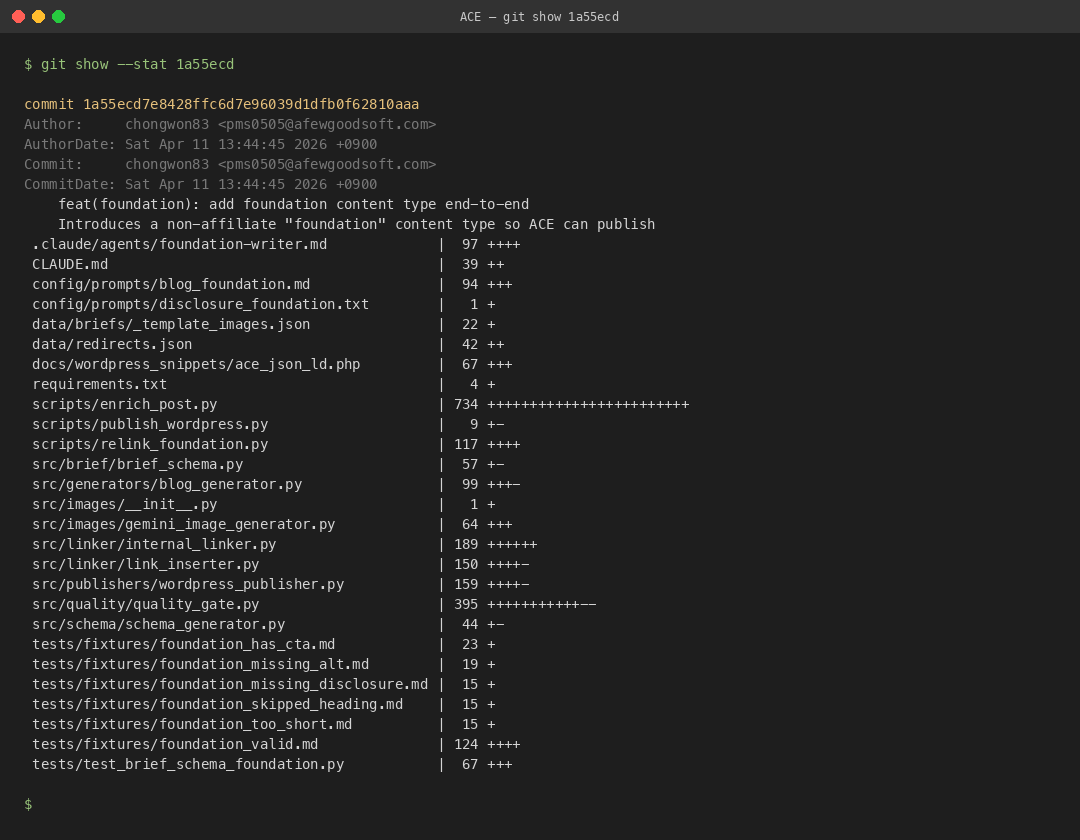
하이라이트는 가장 위에 있는 커밋 1a55ecd feat(foundation): add foundation content type end-to-end였다. 이 한 커밋에 파일 34개가 변경되고 3,933줄이 추가됐다. Foundation 콘텐츠 타입 — 지금 당신이 읽고 있는 이 글의 형식 — 이 그날 태어났다. 프롬프트 템플릿, 전용 Quality Gate 프로파일, D9 내부 링크 토폴로지, 이미지 enrichment 파이프라인, WordPress 드래프트 발행까지 한 호흡에 연결된 순간이었다. 그날 새벽 3시에 나는 책상에서 혼자 “됐다”라고 소리 내서 말했다. 내 아내가 방문을 열고 “뭐가 됐어?”라고 물었고, 나는 “내 글쓰기 공장이 완성됐어”라고 답했다.
그때까지 내가 작성한 핵심 모듈은 세 개였다. src/quality/quality_gate.py는 531줄로 5가지 기계적 검사(공개 고지, CTA 개수, 단어 수, SEO 메타, leftover placeholder)를 수행한다. src/linker/internal_linker.py는 189줄로 D9 허브 앤 스포크 토폴로지를 구현한다. 이 글이 허브이고, 나머지 5편이 스포크다. 허브는 모든 스포크를 가리키고, 각 스포크는 허브와 인접한 2개 스포크를 가리킨다. scripts/enrich_post.py는 734줄로 Nano Banana 2(Gemini 2.5 Flash Image)로 히어로 이미지를 1장당 약 0.039달러에 생성하고 WordPress 미디어 라이브러리에 업로드한다. 세 파일을 합치면 1,454줄. 비개발자 기준으로 나쁘지 않은 숫자다.
파이썬 초심자인 내가 이 규모의 코드를 짤 수 있었던 건 한 가지 원칙 덕이었다. “한 함수는 최대 50줄, 한 파일은 한 가지 책임.” Claude Code에게 이 원칙을 CLAUDE.md에 박아두고 코드를 요청하니 LLM이 자동으로 작은 단위로 쪼개줬다. 나는 각 함수를 한 번에 하나씩 이해할 수 있었고, 이해가 안 되는 함수는 다시 더 쪼갤 수 있었다. 결과적으로 내 레포에는 50줄을 넘는 함수가 거의 없다. 대부분 20~30줄이다. 그래서 어떤 함수가 실패해도, 나는 그 함수 하나만 놓고 LLM과 대화할 수 있다.
한 가지 더. 나는 처음부터 테스트를 같이 쓰기로 했다. tests/ 폴더에 각 모듈의 단위 테스트를 두고, 커밋하기 전에 pytest를 돌렸다. 테스트를 먼저 쓰는 건 아니다. 그건 내 수준에서 아직 어렵다. 대신 LLM이 함수를 써주면 같은 세션 안에서 “이 함수의 pytest 테스트 3개를 만들어줘”라고 이어서 요청했다. 이 한 단계만 추가해도 내 코드의 신뢰도가 체감상 두 배가 됐다. 밤에 자고 일어나서 “어제 짠 게 진짜 돌아가는 건가”라는 불안이 사라진다.
어떻게 작동하는가
ACE의 동작은 5단계로 쪼갤 수 있다. 나는 이걸 의도적으로 “메인 오케스트레이터 = Claude Code” + “Python = I/O만” 구조로 설계했다. 코드를 최소화하고 LLM이 직접 조율하도록 하는 게 비개발자인 나에게 유지보수가 쉬웠다. 내가 직접 읽을 수 있는 코드 양이 적을수록, 버그가 났을 때 LLM에게 상황을 설명하기 쉽다.
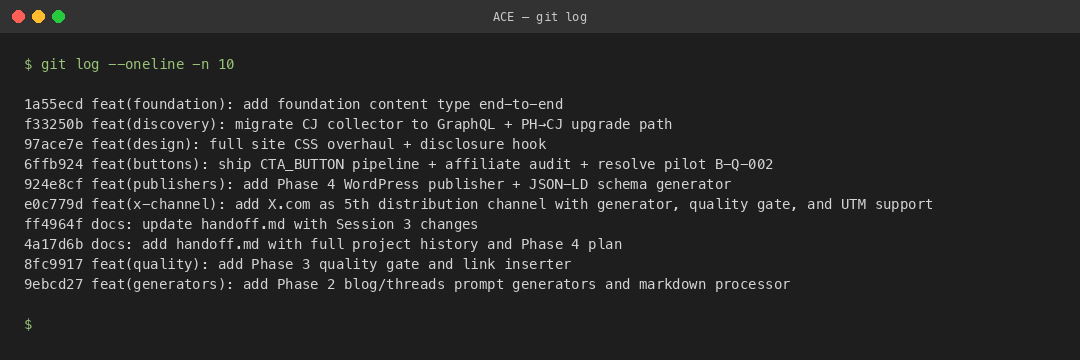
이 구조가 실제로 돌아가고 있다는 증거는 내 레포의 커밋 로그에 그대로 남아 있다. 아래 스크린샷은 git log --oneline | head의 실제 출력이다. 각 커밋이 하나의 단계에 매핑되는 걸 눈으로 확인할 수 있다.
그리고 아래는 Foundation 타입을 한 번에 추가한 그 커밋의 git show --stat이다. 한 커밋에 34개 파일이 변경되고 3,933줄이 추가된 장면은 내 레포의 분기점이다.
- Brief 읽기: Google Sheets의
briefs탭에서brief_id로 한 줄을 읽는다. 제품명, 콘텐츠 타입, angle, proof_points, target_persona, founder_notes, primary_keyword, secondary_keywords 같은 필드가 구조화돼 있다. 한 brief가 한 글의 입력 명세서다. 이 부분은 구글 시트를 콘텐츠 DB로 쓴 이유에서 왜 Notion이 아니라 Sheets였는지 상세히 쓴다. - 프롬프트 채우기:
config/prompts/blog_*.md템플릿을 파이썬이str.replace()로 채워서 stdout에 뿌린다. 생성기는 단 한 줄도 모델을 호출하지 않는다. LLM 호출은 Claude Code 세션이 담당한다. 이 분리 덕에 프롬프트만 고치면 모델 비용 없이 출력을 바꿀 수 있다. - 본문 생성: 메인 오케스트레이터(Opus)가
blog-writer또는foundation-writer서브에이전트(Sonnet)에게 위임한다. 장문 생성은 토큰 비용이 높으니 Sonnet으로, 조율·검수는 Opus로. Foundation 포스트는foundation-writer로, 어필리에이트 포스트는blog-writer로 라우팅된다. 모델 라우팅의 이유는 Claude Code 서브에이전트로 블로그 위임에서 다룬다. - Quality Gate:
python scripts/check_quality.py <file> --content-type foundation. 531줄짜리 검사기가 Hangul character 수, CTA 0개 확인, alt 텍스트 누락, 헤딩 계층 붕괴를 기계적으로 잡아낸다. Foundation 프로파일은 affiliate 프로파일과 검사 항목이 다르다. CTA가 있으면 오히려 실패한다. 통과 기준은 Quality Gate 5단계로 쓰레기 포스트 막기에 나열돼 있다. - Publish:
python scripts/publish_wordpress.py가 워드프레스 REST API에 Basic Auth로 드래프트를 올리고, Schema.orgBlogPosting+BreadcrumbList+ (있다면)FAQPageJSON-LD를〈script〉태그로 꽂는다. 기본 상태가draft인 건 의도적이다. 내가 WP 어드민에서 대표 이미지, 카테고리, Yoast SEO 필드를 한 번 더 확인한 뒤 발행 버튼을 누른다. 이 부분은 WordPress REST API로 Schema.org 자동 주입에서 설명한다.
실제 brief를 읽는 코드는 이렇다. 이건 장난감 예시가 아니라 내 레포에 지금 돌아가는 코드다.
src/briefs/brief_reader.py (발췌):
def read_brief(brief_id: str) -> dict:
"""briefs 탭에서 brief_id 한 줄을 dict로 반환."""
client = SheetsClient()
rows = client.get_all_records("briefs")
for row in rows:
if row.get("brief_id") == brief_id:
return row
raise ValueError(f"brief_id not found: {brief_id}")
이 20줄 안에 내 파이프라인의 설계 철학이 다 들어 있다. 단일 책임, 명시적 에러, 외부 상태 주입(SheetsClient를 함수 안에서 생성하지만 단순하게 유지). 구글 시트의 get_all_records() 한 줄이 탭 전체를 dict 리스트로 돌려주기 때문에 나는 컬럼 타입 캐스팅에 신경 쓸 필요가 없었다.
이 파이프라인의 전체 구조를 5단계로 왜 쪼갰는지는 ACE 아키텍처를 5단계로 쪼갠 이유에서 별도로 다룬다. 각 단계가 왜 독립적이어야 하는지, 어느 단계를 덜 자동화하기로 했는지의 trade-off가 핵심이다. 특히 Publish 단계를 일부러 draft로 멈추는 결정은 자동화 매니아에게는 반직관적일 수 있다. 하지만 “매일 한 편”을 실제로 6개월 돌려보면 저 수동 확인 1분이 무엇보다 값지다는 걸 알게 된다.
한 가지 더 설명할 가치가 있는 건, 각 단계 사이의 “상태 전이” 규칙이다. 한 brief의 status 필드는 ready → in_progress → generated → published → failed 순서로만 움직일 수 있다. 역방향은 금지다. 이 단방향 상태 머신이 있어서 나는 매일 아침 python scripts/list_briefs.py --status=ready를 돌려 “오늘 내가 처리할 것”을 한눈에 볼 수 있고, --status=failed로 “내가 돌아와서 고쳐야 할 것”을 따로 본다. 상태를 Google Sheets에 두는 것의 부수 효과다. 눈으로 볼 수 있는 DB는 눈으로 확인하는 작업 흐름을 가능하게 한다. 이건 숫자로 측정 안 되는 종류의 생산성 이득이지만, 매일 2시간이 2.5시간이 되면 한 달에 15시간 차이가 난다.
내가 틀렸던 지점
나는 처음에 Notion API로 콘텐츠 DB를 만들려고 했다. Notion은 화면이 예쁘고, 내가 이미 매일 쓰고 있었고, 무료 플랜으로 충분해 보였다. 3일간 나는 properties 스키마 캐스팅과 씨름했다. 같은 “제목” 필드가 title, rich_text, select 중 어느 타입인지에 따라 API 응답 구조가 미묘하게 달라졌고, rollup과 relation 필드는 페이지네이션까지 직접 처리해야 했다. 내 코드의 절반이 Notion 응답을 파싱하는 데 쓰였다. 정작 “brief 한 줄 읽기”라는 본래 목적은 한 발짝도 진도가 안 나갔다.
4일째 새벽, 나는 포기하고 구글 시트로 갈아탔다. gspread 라이브러리로 30줄 만에 동일 기능이 동작했다. get_all_records() 한 줄이면 탭 전체를 파이썬 dict의 리스트로 돌려줬다. 한글 컬럼도 문제없었고, 내가 브라우저에서 직접 편집해도 스크립트가 즉시 그 변화를 읽었다. 내가 틀린 건 “예쁜 UI = 좋은 DB”라는 가정이었다. 비개발자 1인 프로젝트에서 DB는 내가 브라우저로 편집할 수 있고, 스크립트로 30줄 안에 읽을 수 있으면 그걸로 충분하다. 구글 시트가 그 두 가지를 다 만족했고, Notion은 두 번째를 만족하지 못했다.
그때 버린 Notion 어댑터 코드는 약 180줄이었다. 지금은 같은 역할을 src/utils/sheets_client.py가 90줄로 처리한다. 반으로 줄었다. 그리고 더 중요하게는, 내가 그 90줄을 전부 이해하고 있다. Notion 어댑터 180줄은 내가 이해하지 못한 채 “돌아가기만 하는” 코드였다. 이해하지 못하는 코드는 한 달 뒤 버그가 나면 손을 댈 수 없다. 이 경험이 그 뒤의 모든 기술 선택에 그림자를 드리웠다. “예쁜 것”보다 “내가 이해할 수 있는 것”을 고르는 원칙이 이때 세워졌다.
돌이켜보면 이 3일의 시행착오는 내 시간으로 계산하면 6시간 정도의 손실이었다. 하지만 교훈의 가치는 그보다 훨씬 크다. 비슷한 함정 — “내가 이미 쓰고 있으니까 익숙하다”는 이유로 부적합한 도구를 고르는 것 — 이 그 뒤 최소 두 번 더 나를 노렸는데, 매번 Notion 사건이 떠올라서 한 발짝 물러섰다. 한 번은 데이터 시각화를 Observable로 하려다가 단순한 matplotlib PNG로 바꿨고, 한 번은 프롬프트 버전 관리를 Git submodule로 하려다가 그냥 config/prompts/ 폴더에 평문으로 두기로 했다. 둘 다 “내가 이해하는 쪽”이 이겼다.
따라해보고 싶다면
비슷한 상황 — 도메인 권위 0, 예산 월 50달러 미만, 코딩 경험 적음 — 이라면 이 순서를 추천한다.
- 도구 세팅: Cursor Pro 월 20달러 + Claude Pro 월 20달러 + 도메인 연 2달러(.xyz) + 워드프레스 자체 호스팅(VPS 월 6달러). 초기 월 고정비 48달러 선에서 시작할 수 있다. Discovery에 Keywords Everywhere를 붙이면 10만 크레딧당 10달러가 더 든다. 풀 세팅이어도 월 60달러를 잘 안 넘긴다.
- 노트 먼저: 종이에 파이프라인 단계를 손으로 그려라. 코드 한 줄 쓰기 전에 “무엇이 입력이고 무엇이 출력인가”를 명확히 해야 LLM에게 시킬 작업 단위가 쪼개진다. 이 노트가 없으면 Claude Code 세션이 20분 만에 옆길로 샌다.
- 레포 초기화:
git init+ 빈CLAUDE.md+ 빈main.py. 그리고 Claude Code에게 “이 프로젝트의 CLAUDE.md를 브레인스토밍으로 함께 써보자”라고 시켜라. 이 파일이 LLM의 영구 기억이 된다. 내 CLAUDE.md는 지금 150줄이 넘고, 프로젝트 목적, 모델 라우팅 규칙, 가능한 스크립트 목록, 콘텐츠 타입 정의, Google Sheets 탭 스키마가 전부 여기에 적혀 있다. - 한 커밋에 한 단계: 내 레포의 초기 10개 커밋을 보면 각 커밋이 정확히 하나의 파이프라인 단계에 매핑돼 있다.
2dac25d feat(sheets),924e8cf feat(briefs),30bde34 feat(discovery), 이런 식이다. 이 원칙은 나중에 디버깅할 때 구원투수가 된다. - 이미지는 마지막에: Nano Banana 2 한 장이 약 0.039달러, 글당 1장이면 한 달 30편 기준 약 1.17달러다. 저렴하지만 글의 완성도가 먼저다. 이미지는 Quality Gate를 통과한 뒤에 붙여라. 반대로 하면 버려지는 이미지가 생긴다.
- 매일 밤
handoff.md: 세션 종료 5분 전에 오늘 한 일, 막힌 곳, 내일 할 일을 3~5줄로 적어라. 다음날 이 파일 하나로 컨텍스트가 복원된다. LLM 세션이 “처음부터 다시 설명하는” 비용을 절반으로 줄여준다.
예상 소요 시간은 내 기준 3주 매일 2시간, 총 40~45시간이었다. Anthropic 공식 문서의 Sub-agents 섹션은 최소 3번 정독을 추천한다. 내가 가장 많이 막힌 곳이 거기였다. 서브에이전트의 모델 필드, 시스템 프롬프트, 허용 도구 범위를 공식 문서 그대로 쓰지 않고 내 마음대로 뜯어고쳤다가 반나절을 날렸다.
난이도에 대해 정직하게 말하면, 나는 이 여정이 “쉬웠다”고 말할 생각은 없다. 어려운 순간이 있었다. 특히 서브에이전트 위임 경계를 처음 이해할 때, 그리고 WordPress REST API의 인증 헤더가 왜 실패하는지 디버깅할 때. 하지만 어려운 것과 불가능한 것은 다르다. 비개발자에게 이 프로젝트는 어렵지만 가능하다. 필요한 건 매일 2시간의 집중과, 모르는 것을 모른다고 말할 용기와, 자기가 이해하지 못한 코드는 커밋하지 않겠다는 고집이다. 이 세 가지가 있으면 LLM이 나머지를 메워준다.
FAQ
Q1. 개발 경험이 정말 없어도 ACE를 복제할 수 있나요?
파이썬 문법을 전혀 모르면 어렵다. 하지만 엑셀 VBA나 구글 앱스 스크립트를 써본 적이 있다면 가능하다. 나는 Claude Code에게 “이 에러 메시지 무슨 뜻이야?”를 하루에 20번씩 물었다. 모르는 걸 모른다고 말할 수 있으면 된다. 진짜 어려웠던 건 문법이 아니라, 내가 만들고 싶은 것을 정확한 언어로 설명하는 연습이었다. 그건 코딩보다는 기획에 가까웠다.
Q2. 월 40달러로 정말 돌아가나요?
고정비 기준 그렇다. Cursor Pro 20달러, Claude Pro 20달러다. 변동비는 이미지 생성에 Nano Banana 2 0.039달러/장, 배포할 WordPress 호스팅이 월 6달러 내외. Discovery 단계에서 Keywords Everywhere를 붙이면 10달러/10만 크레딧이 더 든다. 풀 세팅이어도 월 60달러를 잘 안 넘긴다. 비교하자면 Surfer SEO는 월 89달러부터, Jasper는 월 49달러부터, Copy.ai는 월 49달러부터다. 내가 세 도구를 다 구독하면 월 187달러인데, ACE는 그 3분의 1 미만이면서 출력물을 100% 내가 통제한다.
Q3. Impact Marketplace에 거절당했는데 어떻게 어필리에이트 수익을 내나요?
이 시리즈의 목표는 “거절당한 상태에서도 승인될 수 있는 도메인 권위를 만드는 것”이다. Foundation 6편은 어필리에이트 링크가 0이다. 대신 EEAT 신호(1인칭, 실제 커밋, 구체적 실패 경험)로 도메인의 신뢰 자본을 먼저 쌓는다. 3~6개월 뒤 다시 Impact에 지원할 때의 승률이 이 6편의 존재 여부로 바뀐다는 가설이다. 동시에 Foundation 6편이 발행되는 동안 나는 상대적으로 심사가 느슨한 중소 네트워크(CJ Affiliate, 파트너스 프로그램 직접 신청)로 먼저 수익 씨앗을 심는다.
Q4. 왜 하필 Claude Code인가요? ChatGPT나 Copilot은 안 되나요?
되긴 된다. 내가 Claude Code를 고른 이유는 세 가지다. (1) 서브에이전트 모델 라우팅(Opus 조율 + Sonnet 장문)으로 토큰 비용을 의도적으로 쪼갤 수 있다. (2) CLAUDE.md 영구 메모리로 프로젝트 컨텍스트가 세션 간 유지된다. (3) bash 실행 권한이 있어서 python scripts/check_quality.py까지 한 세션 안에서 끝난다. 다른 도구로도 재현 가능하지만 내 조합 기준 Claude Code가 가장 매끄러웠다. 결정적인 건 (2)번이었다. 매일 밤 내가 돌아왔을 때 LLM이 어제의 나를 기억하고 있다는 감각은 다른 도구에서 쉽게 얻지 못했다.
Q5. 이 글의 다음은 뭔가요?
다음 글 ACE 아키텍처를 5단계로 쪼갠 이유에서 5단계 파이프라인의 trade-off를 하나씩 뜯는다. 왜 생성과 검수를 분리했는지, 왜 Publish를 기본 draft로 두는지, 왜 Discovery를 아예 다른 스크립트 번들로 뺐는지 — 의사결정의 이유가 전부 거기에 있다. 그 뒤 구글 시트를 콘텐츠 DB로 쓴 이유, Claude Code 서브에이전트로 블로그 위임, Quality Gate 5단계로 쓰레기 포스트 막기, WordPress REST API로 Schema.org 자동 주입 순서로 이어진다.
[NEWSLETTER_SIGNUP]
답글 남기기