내가 1인 콘텐츠 엔진을 5개 모듈로 쪼개 만든 이유
이 글은 제가 ACE(Affiliate Content Engine)를 직접 만들면서 기록한 경험담입니다. 이 글에는 어필리에이트 링크가 포함되어 있지 않습니다. 언급되는 도구는 모두 제가 실제로 사용 중인 것들이며, 링크는 투명성을 위해 공개된 슬러그 리다이렉트(/go/{slug})를 통해 이동합니다.
왜 이 문제가 중요한가
내가 처음 ACE(Affiliate Content Engine)를 설계했을 때는 generate_blog.py 하나에 모든 걸 다 넣어둘 생각이었다. 브리프를 읽고, 프롬프트를 채우고, 글을 쓰고, 링크를 끼우고, 스키마를 만들고, 워드프레스로 올리는 것까지 한 파일이면 충분할 것 같았다. 비개발자 입장에서 파일이 적을수록 이해하기 쉽다고 믿었기 때문이다. 함수 다섯 개쯤 겹쳐 쓰고, 맨 아래 if __name__ == "__main__": 하나 박아두면 끝날 거라 생각했다.
그 믿음이 깨진 건 세 번째 글을 돌려본 날이었다. 품질 체크에서 메타 디스크립션 길이만 걸렸는데, 수정하려면 전체 파이프라인을 처음부터 다시 돌려야 했다. 프롬프트가 다시 API를 때렸고, 나는 같은 본문을 다시 생성하느라 토큰을 두 번 태웠다. 화면에는 내가 이미 합격시켰던 문단들이 다시 한 줄씩 흘러나왔고, 그걸 보는 동안 나는 점점 화가 났다. 바꿔야 할 건 메타 디스크립션 한 줄뿐이었는데.
그때 깨달았다. 1인 운영에서 중요한 건 코드 줄 수가 아니라 rerun 비용이 얼마나 싸게 먹히는가였다. 매번 글 하나를 완성하는 데 3시간이 걸린다면, 재실행 한 번은 30초 안에 끝나야 한다. 한 덩어리 스크립트로는 절대 그 조건을 맞출 수 없었다. 모든 단계가 직렬로 엮여 있으면, 중간 한 군데만 틀어져도 앞 단계가 통째로 다시 돌아간다. 돈이 새는 게 아니라 시간이 새는 게 더 뼈아팠다.
나한테는 투자자도, 팀원도, QA 엔지니어도 없었다. 오직 저녁 시간 2~3시간과, 이미 한도가 정해진 API 크레딧과, 새벽에 다시 돌려봐야 내일 아침까지 글이 나올지 걱정되는 마음만 있었다. 그래서 아키텍처를 “많은 글을 뽑기 위한 공장”이 아니라 “실수해도 싸게 되돌릴 수 있는 구조”로 바꿔야 했다. 하루에 여러 편을 뽑는 것보다, 한 편을 꺼내 놓고 마음에 안 드는 부분을 마음껏 고칠 수 있는 여유가 훨씬 더 귀했다.
비슷한 고민을 하는 사람을 나는 몇 명 안다. 본업이 따로 있는 마케터, 부업으로 뉴스레터를 시작한 기획자, 제품 리뷰를 쌓아 올리려는 1인 쇼핑몰 운영자. 우리는 공통적으로 “코드는 조금 배웠지만 시스템을 만들어본 적은 없는” 사람들이다. 그래서 우리에겐 “한 번에 완벽한 공장”보다 “한 조각씩 고쳐도 무너지지 않는 골조”가 필요하다. 이 글이 그 골조를 어떻게 세우는지에 대한 힌트가 되면 좋겠다.
이 글은 내가 한 덩어리 설계를 버리고 brief → generate → quality gate → link insert → publish 다섯 단계로 분해한 기록이다. 왜 하필 5개였는지, 각 단계가 무엇을 독립적으로 책임지는지, 그리고 비개발자인 내가 어떤 기준으로 경계선을 그었는지를 적었다. 아키텍처 이야기를 하지만 추상적인 용어는 쓰지 않으려 한다. 모든 이야기는 내 레포의 실제 파일 경로와 커밋 해시에 붙어 있다. 내가 했던 실수까지 포함해서 말이다.
내가 실제로 한 것
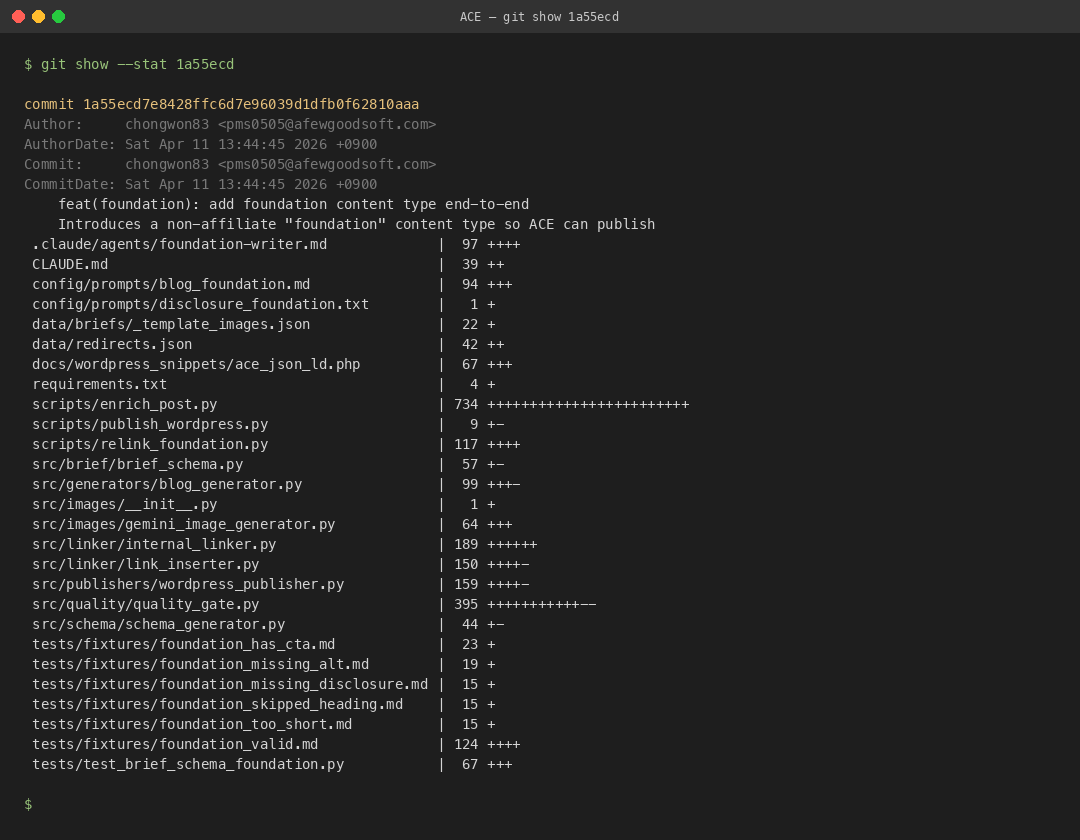
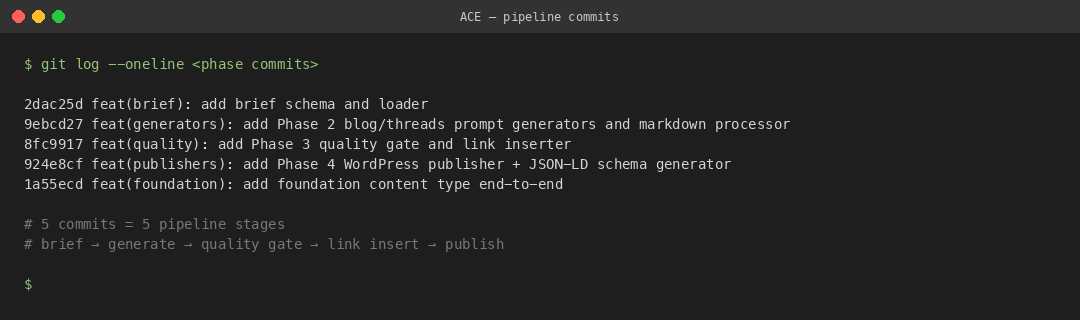
나는 5개의 커밋에 5개의 단계를 하나씩 넣었다. 한 커밋에 한 모듈이라는 규칙을 스스로에게 강제했고, 그게 지금도 ACE를 지탱하는 뼈대가 됐다. 이 규칙이 왜 중요한지 나는 뒤늦게 알았다. 한 커밋에 여러 단계를 섞어 넣으면, 나중에 어느 줄이 어떤 역할을 하는지 되짚기가 어려워진다. 반대로 커밋 하나가 모듈 하나라면, 로그를 훑는 것만으로 파이프라인의 뼈대가 한눈에 보인다.
이걸 가능하게 만든 건 git log를 거꾸로 훑으면서 “이 커밋에서 내가 어떤 고통을 해결하려 했나”를 한 줄씩 적어본 습관이었다. 기술 블로그에 흔히 나오는 “클린 아키텍처” 이론서가 아니라, 내 터미널에 찍힌 빨간 에러 메시지들이 내 설계 선생님이었다.
커밋 타임라인은 이렇게 흘렀다.
2dac25d feat(brief): add brief schema and loader— 1단계. 구글 시트의 브리프 행을 파이썬 객체로 읽어오는 로더다. 파일은src/brief/brief_loader.py. 이 모듈은 오직 “시트 한 행을 검증된Brief객체로 바꾼다”는 일만 한다. 콘텐츠 생성은 알지도 못한다.9ebcd27 feat(generators): add Phase 2 blog/threads prompt generators— 2단계.src/generators/blog_generator.py가 브리프 객체를 받아서config/prompts/blog_comparison.md같은 템플릿을str.replace()로 채운다. 이 모듈도 API를 직접 때리지 않는다. 프롬프트 텍스트를 stdout으로 내보낼 뿐이다. 실제로 Claude Code(Opus/Sonnet)가 그걸 받아서 본문을 써준다.8fc9917 feat(quality): add Phase 3 quality gate and link inserter— 3단계 + 4단계.src/quality/quality_gate.py는 현재 531줄이고,src/linker/internal_linker.py는 189줄이다. 두 모듈은 이미 쓰여진 마크다운 파일을 파일 경로 하나로 받아서 검증하거나 링크를 꽂는다.924e8cf feat(publishers): add Phase 4 WordPress publisher + JSON-LD schema generator— 5단계.src/publishers/wordpress_publisher.py가 완성된 마크다운을 워드프레스 REST API로 올린다. 스키마 주입은 그 직전에 따로 돌아간다.1a55ecd feat(foundation): add foundation content type end-to-end— 파운데이션 콘텐츠 타입 추가. 이건 기존 5단계 위에 얹은 프로파일 전환이지 새로운 단계가 아니다. 한 덩어리였다면 이걸 얹는 순간 전체를 다 건드려야 했을 것이다.
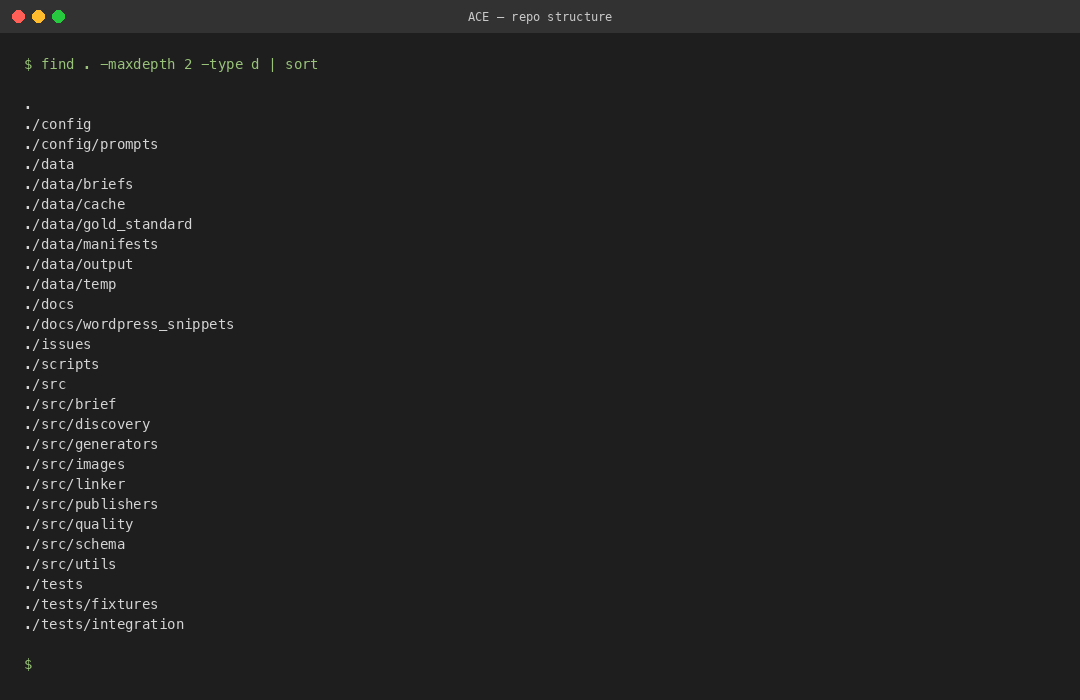
나는 scripts/ 디렉토리를 명시적으로 두껍게 유지했다. 각 단계가 독립 CLI 진입점을 하나씩 갖도록 했다. scripts/read_brief.py, scripts/generate_blog.py, scripts/check_quality.py, scripts/insert_links.py, scripts/publish_wordpress.py. 이게 얇은 파이썬 래퍼라는 사실이 중요하다. 내용물은 src/ 아래 모듈이 다 쥐고 있고, scripts/는 그냥 문 손잡이에 불과하다. 문 손잡이가 얇아야 내가 망치로 두드릴 때 안쪽 기계가 다치지 않는다.
scripts/ 아래에는 지금 20개가 넘는 CLI 진입점이 쌓여 있다. 처음엔 과하다고 느꼈지만, 쓰다 보니 이게 가장 빠른 디버깅 도구라는 걸 알았다. 어느 단계가 터지든 해당 스크립트만 따로 돌려서 로그를 확인할 수 있다. 두 단계 사이 어딘가에서 데이터가 이상하게 변했다면, 각 스크립트를 순서대로 돌려서 어느 파일이 바뀌는 순간 이상해지는지 추적한다. 이건 pdb 같은 디버거를 쓸 줄 모르는 비개발자에게는 엄청난 무기다.
이렇게 만들고 나니, 어떤 단계에서 실패해도 나는 그 단계부터 다시 돌리면 됐다. 품질 체크가 터지면 check_quality.py만 다시 돌린다. 링크가 하나 빠졌다면 insert_links.py만 다시 돌린다. 생성 단계로 되돌아가지 않는다. 이 왜 비개발자가 이걸 직접 만들었나의 출발점이었던 “내가 오늘 밤 안에 글을 내고 자고 싶다”는 요구는 결국 이 경계선 덕분에 유지됐다.
모듈 이름을 정할 때도 규칙이 있었다. 각 파일 이름은 동사 한 개 + 명사 한 개로만 짓는다. read_brief, generate_blog, check_quality, insert_links, publish_wordpress. do_everything.py나 pipeline_handler.py 같은 모호한 이름은 절대 쓰지 않는다. 이름이 모호해지는 순간 그 모듈은 책임이 너무 많아진다는 신호였고, 그럴 때는 항상 두 개로 쪼개야 했다.
어떻게 작동하는가
파이프라인이 돌아가는 순서를 번호로 적어본다. 중간 중간 어떤 파일이 뭘 책임지는지 같이 적는다.
- 브리프 로드.
scripts/read_brief.py B-F-002를 치면src/brief/brief_loader.py가 구글 시트의briefs탭에서 한 행을 읽고 검증한 뒤 JSON으로 뱉는다. 필수 필드가 비어 있으면 여기서 멈춘다. 검증은pydantic모델 하나로 묶여 있어서, 시트에 컬럼을 추가해도 모델만 수정하면 파이프라인 전체가 새 필드를 알아본다. - 프롬프트 생성.
scripts/generate_blog.py B-F-002가config/prompts/blog_foundation.md를 열어primary_keyword자리표시자를 실제 브리프 값으로 바꾼다. 그 결과가 stdout으로 흘러나오고, Claude Code가 이걸 받아서 본문을 써준다. 본문 생성 자체는 파이썬 코드 밖에서 일어난다는 점이 중요하다. 모델을 바꿔도 이 모듈은 그대로다. Opus에서 Sonnet으로, 혹은 Sonnet에서 다른 모델로 갈아탈 때 내 파이썬 코드는 한 줄도 건드리지 않는다. - 품질 게이트.
scripts/check_quality.py data/output/blog/B-F-002.md --content-type foundation을 돌린다.src/quality/quality_gate.py는 파일 경로만 받는다. 파일 내용을 읽고, 프로파일에 맞는 체크 목록을 돌리고, 결과를 dict로 돌려준다. 프롬프트도 API도 다시 때리지 않는다. 실패하면 어느 체크에서 걸렸는지 이름과 이유가 그대로 출력되니, 어디를 고쳐야 할지 바로 보인다. - 링크 삽입.
scripts/insert_links.py가 본문 안의 플레이스홀더 토큰과[LINK:...]패턴을 실제 URL로 치환한다. 파운데이션 글은 제휴 링크가 없어서 이 마커만/go/<slug>리다이렉트로 바뀐다. 리다이렉트 테이블은data/redirects.json에 있고, 새 도구를 추가하면 그 파일만 갱신한다. - 발행.
scripts/publish_wordpress.py가src/publishers/wordpress_publisher.py를 호출해 워드프레스 REST API로 초안을 올린다. 스키마 JSON-LD는 발행 직전에 HTML 말미에〈script type="application/ld+json"〉으로 주입된다. 기본 상태는draft라서, 내가 워드프레스에 들어가서 카테고리와 대표 이미지를 확인한 뒤 직접publish버튼을 누를 수 있다. 완전 자동화는 일부러 피했다. 마지막 눈 한 번은 내가 꼭 넣고 싶었다.
각 단계가 독립 모듈이라는 건, 코드에서 어떻게 보일까? quality_gate.py의 핵심은 다음과 같은 레지스트리 패턴이다.
# src/quality/quality_gate.py (발췌)
CHECK_REGISTRY = {
"affiliate_default": [
check_disclosure,
check_no_leftover_placeholders,
check_cta_count,
check_word_count,
check_seo_meta,
],
"foundation": [
check_foundation_disclosure,
check_no_leftover_placeholders,
check_no_cta,
check_hangul_char_count,
check_heading_hierarchy,
check_alt_text,
],
}
def run_checks(markdown_path: Path, profile: str) -> dict:
content = markdown_path.read_text(encoding="utf-8")
checks = CHECK_REGISTRY[profile]
results = {fn.__name__: fn(content) for fn in checks}
return {"passed": all(r["ok"] for r in results.values()), "checks": results}
CHECK_REGISTRY가 있어서 파운데이션 글에는 check_no_cta가 걸리고 일반 제휴 글에는 check_cta_count가 걸린다. 콘텐츠 타입이 하나 추가돼도 나는 프로파일 하나만 새로 등록하면 된다. 생성 모듈이나 발행 모듈은 수정하지 않는다. 이게 내가 레고 블록처럼 맞추고 싶었던 바로 그 모양이다.
그리고 이 레지스트리가 가능한 건 품질 게이트가 파일을 입력으로 받기 때문이다. 프롬프트 문자열을 받아서 검증하는 구조였다면 절대 이렇게 깔끔하게 분리되지 않았을 것이다. 내가 한참 돌아서 배운 교훈이 여기에 있다.
링크 삽입 모듈도 같은 원칙을 따른다. src/linker/internal_linker.py는 189줄이고, 파일 경로와 브리프 ID만 받는다. 내부 링크는 FOUNDATION_SLUGS 레지스트리에서 찾아 D9 토폴로지대로 꽂고, 외부 [Cursor](https://potato-labs.xyz/go/cursor/) 같은 토큰은 data/redirects.json을 읽어 /go/cursor로 치환한다. 이 모듈도 품질 게이트를 모르고, 브리프 로더를 모르고, 워드프레스를 모른다. 자기 일만 한다.
이 구조가 주는 또 하나의 장점은 테스트 작성이 쉬워진다는 것이다. 각 모듈이 파일 경로 입력과 파일 출력(또는 dict 반환)만 가지니까, 테스트에서 임시 디렉토리에 가짜 파일을 하나 놓고 함수를 부르면 끝이다. 나는 tests/fixtures/ 아래에 작은 샘플 마크다운을 몇 개 두고, 그걸로 quality_gate.run_checks를 호출하는 테스트를 돌린다. API를 때리지도 않고, 네트워크도 없고, 몇 초면 끝난다.
내가 틀렸던 지점
나는 처음에 quality gate를 generate 단계에 묶어놨다. 이유는 단순했다. “어차피 본문을 만들자마자 체크해야 할 테니 같은 스크립트 안에 두면 편하지 않나?” 라고 생각했기 때문이다. 실제 초기 구조에서 scripts/generate_blog.py의 마지막 30줄은 방금 만든 본문을 바로 검증하는 코드였다. 심지어 나는 그걸 “원스톱”이라 부르며 뿌듯해했다. 명령어 하나로 글이 나오고, 검증까지 끝난다고 말이다.
문제는 세 번째 글을 돌린 날 드러났다. meta_description이 102자로 나왔는데 상한선이 95자였다. 앞으로 몇 글자만 자르면 되는 수정이었다. 그런데 당시 구조에서는 그 체크를 다시 돌리려면 generate_blog.py를 통째로 다시 실행해야 했고, 그 말은 Claude Code가 본문을 처음부터 다시 써낸다는 뜻이었다. rerun 한 번에 토큰을 두 번 태운 셈이다. 본문 자체는 멀쩡했는데도. 그날 밤 나는 같은 본문을 세 번 생성하면서 “왜 내가 이 짓을 하고 있지?” 라는 질문을 반복했다.
그래서 나는 8fc9917 feat(quality): add Phase 3 quality gate and link inserter 커밋에서 품질 게이트를 독립 모듈로 뽑아냈다. src/quality/quality_gate.py 531줄은 파일 경로 하나만 받는 함수로 다시 쓰여졌다. 입력이 “방금 생성된 본문 문자열”이 아니라 “디스크에 저장된 마크다운 파일”이 된 순간, rerun 비용은 0에 수렴했다. 토큰은 전혀 쓰지 않고, 수정한 파일을 다시 읽어서 다시 검증할 뿐이었다. 나는 그날 처음으로 check_quality.py를 10번 연속으로 돌려봤는데, 터미널에 passed: True가 뜨기까지 1분도 걸리지 않았다.
이 경험에서 내가 더 깊이 배운 건 “입력의 모양을 바꾸면 모듈의 경계가 바뀐다”는 사실이었다. 입력이 문자열이면 모듈은 호출자와 붙어 있게 된다. 입력이 파일이면 모듈은 호출자와 완전히 떨어진다. 파일이라는 공통 인터페이스가 있는 덕분에, 나는 단계별로 원하는 만큼 재시도할 수 있게 됐다. 파일 시스템이 내 메시지 큐 역할을 해주는 셈이다.
비개발자 입장에서 이 교훈이 특히 값지다고 느끼는 이유는, “파일”이라는 개념은 누구나 이해할 수 있기 때문이다. 메시지 큐, 이벤트 버스, 워크플로우 엔진 같은 용어는 내가 두 달을 파도 제대로 설명하기 어려웠다. 반면 “마크다운 파일 하나가 단계 사이를 옮겨다닌다”는 모델은 내 머릿속에서 한 장의 그림으로 그려진다. 그 그림이 선명한 한, 나는 구조를 잊어버릴 수 없다.
교훈은 이렇다. 모듈 경계는 “같이 실행되는가”로 긋는 게 아니라 “따로 다시 돌릴 수 있어야 하는가”로 그어야 한다. 이걸 알고 나서는 다른 단계들도 같은 기준으로 다시 점검했고, scripts/enrich_post.py(734줄)도 생성과 완전히 분리된 독립 진입점으로 만들었다. 파운데이션 글의 이미지 업로드가 네트워크 문제로 실패해도, 본문 생성은 건드리지 않고 enrich_post.py만 다시 돌리면 된다.
이 경험은 이후 내가 새 기능을 추가할 때마다 가장 먼저 물어보는 질문이 됐다. “이 기능이 실패하면, 나는 어디서부터 다시 돌려야 하지?” 그 답이 “전체”라면 그건 설계가 잘못된 것이다. 답이 “이 한 단계만”이 되도록 경계선을 그어야 한다. 그게 내가 531줄짜리 파이썬 파일 앞에서 배운 가장 비싼 교훈이었다.
따라해보고 싶다면
이 구조는 복잡한 도구 없이도 복제할 수 있다. 내가 실제로 밟은 순서는 이렇다.
- 스프레드시트 한 장으로 데이터베이스를 대신하라. 구글 시트 한 탭에 브리프 행을 쌓고, 파이썬에서
gspread로 읽어오면 된다. 구조를 미리 고민할 필요 없이 컬럼을 그냥 추가하면 된다. 자세한 이유는 구글 시트를 콘텐츠 DB로 쓴 이유에 따로 적어뒀다. - 5단계 각각을 독립
scripts/*.py로 만들어라. 각 스크립트는 CLI 인자 하나(보통brief_id)만 받고, 자기 단계만 책임지게 둔다. 500줄이 넘어가면 그 단계가 너무 많은 일을 하고 있다는 신호다. - 파일 경로를 인터페이스로 써라. 단계 간 데이터 전달은 문자열이 아니라 디스크 파일로 한다.
data/output/blog/{brief_id}.md처럼 경로 컨벤션을 먼저 정해두면, 각 단계가 아무 순서로나 재실행돼도 상태가 꼬이지 않는다. - 생성은 파이썬 밖에서. 본문 작성은 Claude Code 같은 AI 도구에 맡기고, 파이썬은 프롬프트 준비와 결과 검증만 한다. 모델을 바꿔도 파이썬 코드는 건드리지 않게 된다. 위임 구조의 구체적 이야기는 Claude Code 서브에이전트 위임에 적어뒀다.
- Cursor를 코드 편집기로, Claude Code를 오케스트레이터로. 나는 Cursor에서 파일을 열어놓고 Claude Code로 전체 파이프라인을 돌린다. 편집기와 실행기를 분리하니 실수로 엉뚱한 파일을 돌리는 일이 줄었다. Cursor는 코드 맥락을 보여주고, Claude Code는 명령을 받아 파이프라인을 꿰어주는 역할이다. 두 도구의 역할이 겹치지 않게 선을 그은 덕분에, 나는 어떤 작업을 어디서 해야 할지 헷갈리지 않는다.
- 매 단계마다 로그 파일을 따로 두어라. 나는
logs/아래에brief.log,generate.log,quality.log,publish.log를 분리해뒀다. 문제가 생기면 해당 단계의 로그 파일만 열어보면 된다.loguru의logger.add()를 단계별로 다르게 설정하는 것만으로도 충분하다. 한 파일에 모든 로그를 몰아넣으면 찾기가 힘들다.
현실적인 기대치: 처음 5단계를 쪼개는 데 나는 주말 이틀을 썼고, 글 한 편을 처음부터 끝까지 돌리는 데 드는 API 비용은 대략 $0.20~$0.40 수준이다. rerun은 생성 단계를 건너뛰면 거의 무료다. 난이도는 파이썬 기본 문법(함수, import, 경로 조작)만 알면 충분하다. 발행까지 이어지는 마지막 조각은 WordPress REST API + Schema.org 자동 주입에서 이어서 다뤘다.
한 가지 덧붙이자면, 처음부터 5단계를 다 만들려고 하지 말라는 말을 꼭 해주고 싶다. 나는 brief 로더 하나 만드는 데 반나절을 썼고, 그 다음 주에 generator를 붙였고, 또 그 다음 주에 quality gate를 얹었다. 한 주 한 단계씩. 그래야 각 단계가 “진짜로 뭘 해야 하는지”가 보인다. 전체 설계를 먼저 그리고 코드를 채우는 방식은, 비개발자가 시작하기엔 너무 무겁다.
나는 지금도 이 레포를 들여다볼 때마다 “이 모듈 하나만 다시 돌리면 되는가”를 되묻는다. 그 질문에 “그렇다”고 답할 수 있는 한, 나는 내 파이프라인이 살아있다고 느낀다. 그게 비개발자 혼자 콘텐츠 공장을 굴리며 얻은 유일한 생존 기술이다. 거창한 용어로 포장하지 않아도, 매일 저녁의 한두 시간을 지켜주는 구조라면 그걸로 충분하다고 믿는다.
FAQ
Q1. 5단계보다 더 잘게 쪼갤 수도 있지 않나?
쪼갤 수는 있지만 나는 일부러 멈췄다. 단계가 늘어날수록 경계에서 버그가 샌다. 5개는 “각 단계가 하나의 명확한 입력과 하나의 명확한 출력을 가질 수 있는” 최소 단위였다. 나중에 enrich_post.py를 추가하긴 했지만, 그건 기존 5단계 사이에 끼는 게 아니라 publish 직전에 병렬로 붙는 단계라 전체 구조를 깨뜨리지 않는다. 경계를 추가할 때는 항상 “이게 정말 따로 rerun될 이유가 있는가?”를 먼저 묻는다. 그 답이 흐릿하면 안 쪼갠다.
Q2. 비개발자가 531줄짜리 quality_gate.py를 직접 다 쓴 건가?
직접 다 썼다고 말하면 거짓말이다. 설계(어떤 체크가 필요한지, 어떤 프로파일로 분기할지)는 내가 정했고, 구현은 Claude Code한테 맡겼다. 중요한 건 내가 그 531줄 중 어느 줄이 어떤 역할을 하는지 설명할 수 있어야 한다는 점이다. CHECK_REGISTRY 패턴을 이해하고 있어서, 새 체크를 추가하라고 할 때 정확히 어디를 건드려야 하는지 지시할 수 있다. 내가 주로 쓰는 지시 문장은 “CHECK_REGISTRY의 foundation 프로파일에 check_hangul_char_count 함수를 추가해줘, 본문에서 5500자 미만이면 실패로 처리해”처럼 파일명과 함수명이 박혀 있는 형태다. 구체적일수록 결과가 예측 가능해진다.
Q3. 이 구조의 가장 큰 약점은 무엇인가?
디스크 파일을 인터페이스로 쓰기 때문에 동시 실행에 취약하다. 두 브리프를 동시에 돌리면 같은 경로를 덮어쓸 수 있다. 지금은 1인 운영이라 순차 실행만 해서 문제가 없지만, 규모가 커지면 브리프 ID별로 디렉토리를 분리하거나 락 파일을 둬야 할 것이다. 그날이 오면 다시 쓰겠지만, 오늘의 문제는 오늘까지만 풀기로 했다. 미래의 나에게 숙제를 남기는 것도 1인 운영의 기술 중 하나다.
[NEWSLETTER_SIGNUP]